Your AI. Your data.
Your environment.
Most AI systems require you to give up control of your data. For many organizations, that is not acceptable — legally, contractually, or ethically. SignaVision provides private AI infrastructure where your data never leaves your environment, your models run on dedicated hardware, and your system operates outside public cloud visibility.
The Problem
Public cloud AI is not viable for everyone.
Organizations are being asked to adopt AI systems that fundamentally conflict with their obligations.
Public Cloud AI
AWS, Azure, GCP, OpenAI API
Your data leaves your control.
Documents, queries, and outputs move through infrastructure you do not own. Governance is dictated by provider policy — not your architecture.
Shared infrastructure introduces systemic risk.
GPU resources are pooled. Performance variability, cold starts, and resource contention are built-in characteristics — not anomalies.
Per-token billing is unpredictable.
Per-token billing creates volatility. Production workloads often exceed initial projections by multiples, not margins.
You have no visibility into the infrastructure.
You cannot inspect or verify how your data is handled internally. Observability is constrained to what the provider exposes.
Private AI Infrastructure
SignaVision
Your data stays in your environment.
Your documents, queries, and model outputs never transit a public cloud network. No cloud provider has infrastructure visibility into your workload. This is not a configuration. The outbound path does not exist.
Dedicated compute, no contention.
Allocated GPU cards are yours for the duration. No cold starts, no queue contention, no shared VRAM fragmentation. Your model stays loaded.
Predictable, fixed allocation cost.
No per-token or per-second billing. Allocation is priced as a fixed arrangement — you know what you pay before you run a single inference.
Built on inert architecture — auditable by design.
Every environment is isolated by structure, not policy. Audit trails exist because the system cannot operate without producing them, not because logging was configured.
What You Get
Not hardware. Capability.
The 30+ RTX 3090 GPUs are the engine. These are what they make possible.
Private AI Workspace
A complete private AI environment: document ingestion, vector search, LLM inference, and API access — all running on your dedicated allocation. Ingest your organization's knowledge. Query it with natural language. Your organization's knowledge becomes queryable — without leaving your control.
Private LLM Hosting
Bring your own model or run an open-weight LLM on dedicated GPU VRAM. Persistent endpoint, no cold starts, no shared queue. Your model, loaded and warm, serving only your requests. No shared queues. No cold starts. No abstraction layers.
RAG Infrastructure
Retrieval-augmented generation pipelines for private enterprise knowledge systems. Embed your documents, index into vector storage, and query with LLM reasoning — entirely within your isolated environment. All contained. Nothing transmitted.
Dedicated GPU Compute
Reserved GPU allocation for training runs, batch inference, and experimentation. Direct access to dedicated RTX 3090 cards. No abstraction layer between your workload and the hardware. No virtualization layers hiding performance realities.
Who It's For
Organizations where data cannot leave.
These are not edge cases. These are entire sectors. They have real AI needs — and legitimate reasons why public cloud is not viable. Engineers and architects looking for the full technical specification can take a technical deep dive into how the system is built.
Law Firms
Client privilege
Universities
FERPA / research
Healthcare
HIPAA compliance
Government
Data sovereignty
Research Labs
Data integrity
Engineering Teams
IP protection
They need AI
Document analysis, knowledge retrieval, inference on proprietary data — the use cases are real and growing.
Public cloud is not viable
Legal obligations, regulatory frameworks, or contractual terms prevent data from transiting third-party infrastructure.
They lack their own GPU cluster
Building and operating private GPU infrastructure is expensive, time-consuming, and outside most organizations' core operations.
For leadership evaluating this
The decision is simpler than the infrastructure: your organization needs AI capability, your data cannot leave, and you do not operate a GPU cluster. This addresses all three — without requiring you to build or manage underlying hardware. It closes the gap without violating your organization’s rules or regulatory constraints.
32 RTX 3090.
768 GB of GPU memory.
Capacity expanding.
The hardware is not the product. It is what makes the product possible at a level of performance and privacy that public cloud cannot replicate.
720+ GB of GPU VRAM means large models run without quantization compromises. 1.0+ PFLOPS of FP32 compute means inference is fast. Dedicated allocation means your workload is not competing with anyone else's.
Capacity building continues.
What 720+ GB VRAM enables
Large model inference without quantization
Full-precision 70B parameter models fit in distributed VRAM across cards — no 4-bit compression forcing quality tradeoffs.
Multiple simultaneous clients
768 GB is enough to load and serve multiple separate model deployments simultaneously — each client's model isolated in its own allocation.
Training runs on private datasets
Fine-tuning and continued pre-training on proprietary data — your model improves on your information without that information leaving your environment.
Vision AI at scale
Real-time video processing, sign language recognition, and multimodal workloads — the same hardware powering SignaVision's own accessibility AI.
Access Architecture
How your data gets there — and how it doesn't leak.
Every connection to the GPU cluster travels through an encrypted WireGuard tunnel. The cluster is not visible on the public internet. It does not respond to unauthenticated traffic. It does not exist to anything outside the tunnel.
Connection path
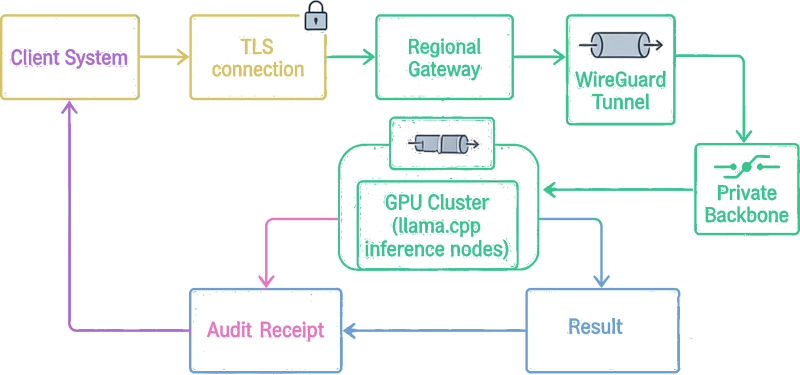
Regional Entry Point
A dedicated regional node (dedicated hardware in a Tier-grade datacenter facility) sits near your location. You connect there — familiar network, low latency, no exotic routing. That node is the gateway into the encrypted tunnel toward the cluster.
WireGuard Tunnel
Every path into the cluster runs through a WireGuard VPN. Peer IPs are whitelisted. The cluster exposes no services outside the tunnel. There is no other way in — not by design, not by accident.
100 GbE Internal Fabric
Inside the cluster, nodes communicate over 100 GbE interconnects. The external interface runs at 2.5 GbE — a 40× bandwidth differential that reflects where the real compute happens: inside, not at the edge.
Silent External Posture
Non-tunnel traffic is dropped without response — no server headers, no error codes, no acknowledgement (NGINX 444 + iptables whitelist). The cluster is effectively dark to anyone not inside the tunnel.
Getting Started
How it works.
You are not buying a datacenter. You are accessing one.
We work with a small number of clients at a time. New deployments are scheduled through a waitlist based on capacity and workload fit.
Tell us what you need
What are you building? What data does it touch? What does your compliance situation look like? We scope the right allocation for your workload before any commitment.
We design your private environment
Isolated compute allocation, model hosting configuration, vector storage, and API access — designed for your specific workload and data handling requirements.
Your environment runs. Your data stays.
Your private AI environment is live on dedicated hardware. Your data processes inside it. No public cloud is involved. No per-token surprises. Predictable, private, and yours.
Data Handling
Stateless by design.
Nothing is kept.
Requests are processed in memory. Nothing is written to persistent storage. When the session ends, the data ends — not archived, not logged, not retained. There is nothing to breach because there is nothing left.
After each run you receive a signed audit receipt: session ID, entry timestamp, exit timestamp, content hash. You hold the record. We do not have one. The receipt proves what happened without preserving what was in it.
Technical security architectureMemory-only processing
Inference runs in GPU and system RAM. Nodes are configured for maximum RAM capacity specifically to support full workload execution in memory — no writes, no spill to disk at any point in the pipeline. Disk writes are not prohibited. They are not implemented.
Client-held audit receipts
Each session produces a receipt: session ID, entry timestamp, exit timestamp, content hash. Record-keeping responsibility passes to you. You have the proof of what ran. We have nothing to subpoena.
Architecture transparency in agreements
Client agreements include the actual hardware specification and data-handling architecture — not just privacy policy language. You see exactly what the system is and how it handles data. Verifiable, not promised.
Machine-to-machine by default
Day-to-day operations are fully automated. No person at SignaVision observes your workload in transit. Human contact is scoped strictly to onboarding, configuration changes, and support escalations.
Private AI for organizations
that cannot compromise on data.
If public cloud AI is not an option, the choice is not between risk and stagnation. There is a third path: private infrastructure. That is what we build.
New clients onboarded via waitlist.